How to Do Web Scraping in Make

Have you ever wondered how to extract valuable data from websites efficiently? Web scraping with Make (formerly Integromat) is your answer! Recent reports indicate that businesses utilizing web scraping technologies experience up to a 40% improvement in data collection efficiency. In this comprehensive guide, I’ll walk you through the steps to scrape any website using Make‘s powerful automation platform.

Whether a beginner or an experienced user, you’ll discover how to transform raw web data into actionable insights. Let’s dive in and unlock the potential of web scraping!
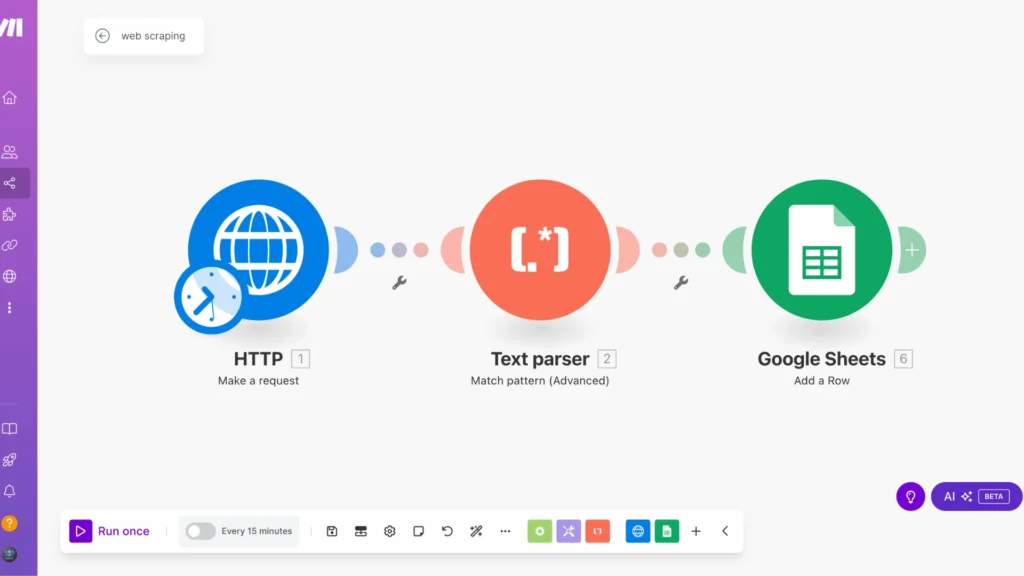
What is Web Scraping?
Web scraping is like having a smart digital assistant that automatically collects and organizes information from websites. Instead of manually copying and pasting data from web pages, web scraping tools do this work for you quickly and efficiently.
Imagine you want to track prices across multiple online stores, gather research data, or monitor social media trends. Manually collecting this information would take hours or even days. This is where web scraping comes in – it automates this entire process, allowing you to extract specific information from websites and save it in a structured format, like a spreadsheet.
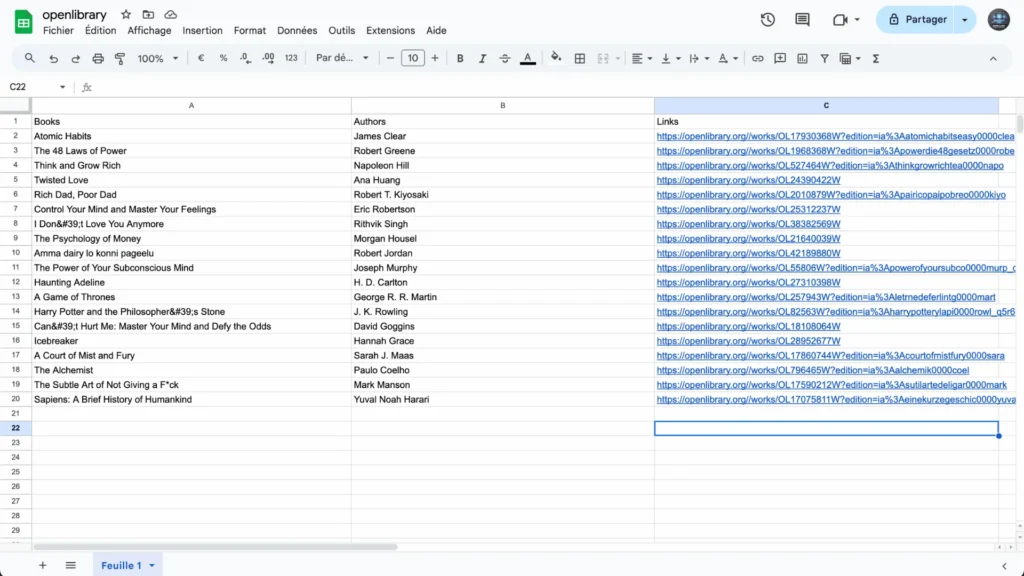
In our tutorial above, we’re using web scraping to collect book information from OpenLibrary, but the possibilities are endless. You could use it to:- Track product prices across e-commerce sites
- Gather real estate listings
- Monitor news articles
- Collect social media posts
- Analyze customer reviews
- Extract contact information from business directories
The best part is that you don’t need to be a programming expert to get started with web scraping. With tools like Make (formerly Integromat), you can build powerful web scraping systems using a visual interface, making it accessible to beginners and advanced users.
Step-by-Step Guide to Creating a Web Scraping Scenario
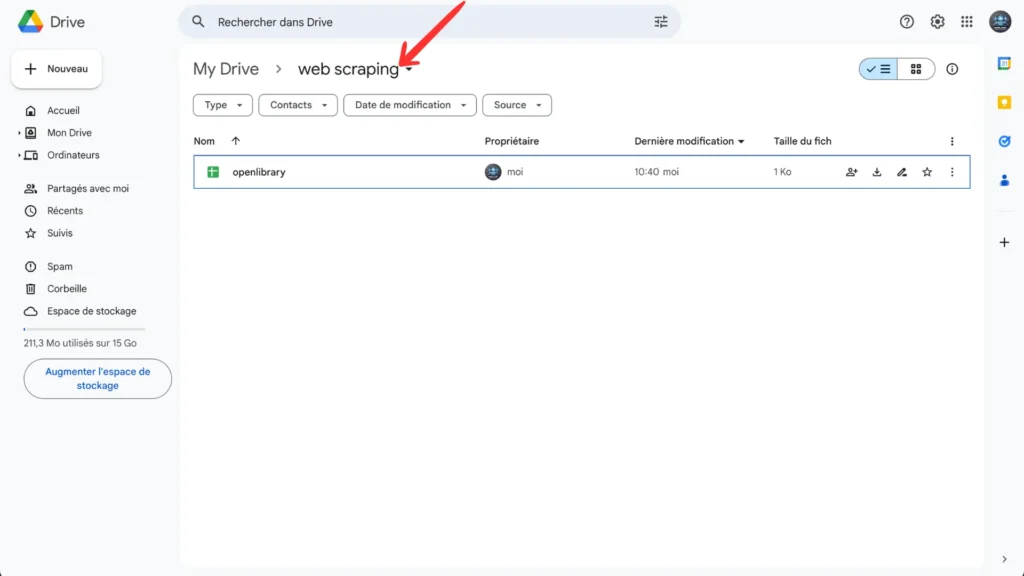
Step 1: Create your folder on Google Drive
Let’s begin by setting up our workspace! Head over to Google Drive and create a new folder – I named mine ‘web scraping,’ but feel free to give it any name that makes sense to you. This will be our home base for all the exciting web scraping projects we’ll work on together.
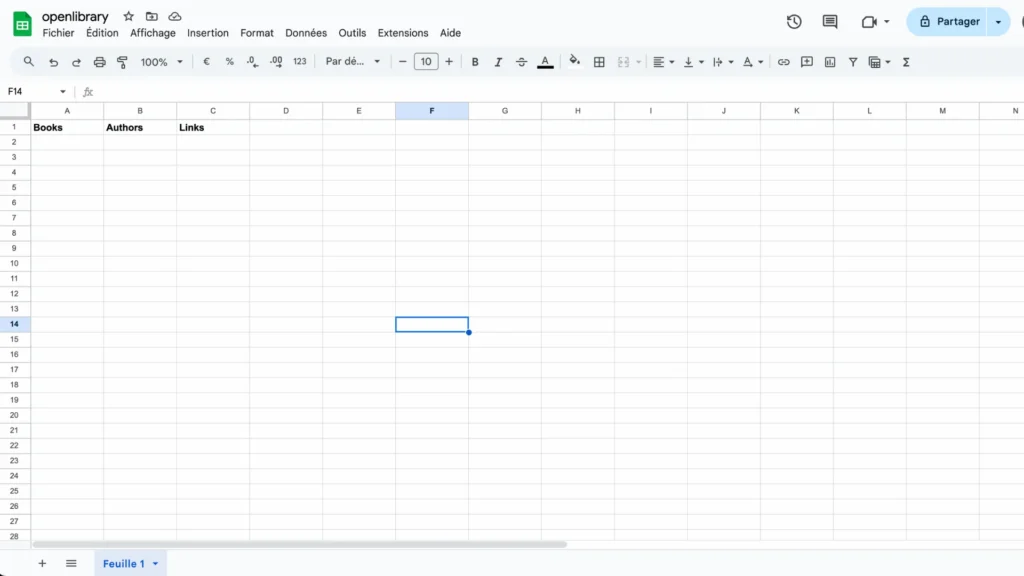
Step 2: Create Your Google Sheets
Now that our folder is set up, let’s create a Google Sheet to organize our data. Take a moment to think about what information you want to collect from your web scraping project. Create columns with clear, descriptive headers matching the data you plan to extract – this will make your work much easier to track and understand later!
Step 3: Create Your Scenario
Next up, we’re heading to Make.com to set up our automation. Don’t worry – it’s completely free to get started! Once you’ve created your account, look for your organization dashboard. There, you’ll spot a blue ‘+ Create a new scenario‘ button in the upper right corner – that’s our next destination!
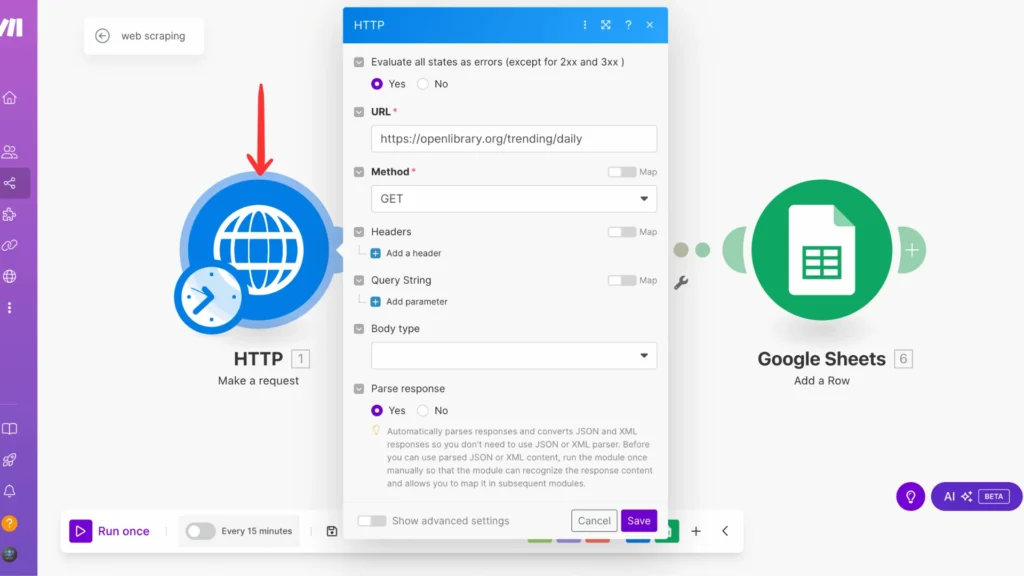
Step 4: Add Your First Module
It’s time to build our first module! Start by adding the ‘Make a request‘ module, our gateway, to fetch data in your new scenario. For this tutorial, I’m using https://openlibrary.org/trending/daily as an example, which gives us a nice list of trending books. But here’s the cool part: you can swap this URL with any website you want to scrape data from!
Step 5: Text Parser
Now comes the fun part – let’s set up our regex module to extract exactly what we want! In this case, we’re targeting three key pieces of information:- The book’s link
- The author’s name
- The book’s title
Think of regex as our data detective, helping us find and grab these details from the webpage. If you’re new to regex patterns, don’t worry – in the next steps, I’ll share the exact patterns you’ll need for each piece of information.
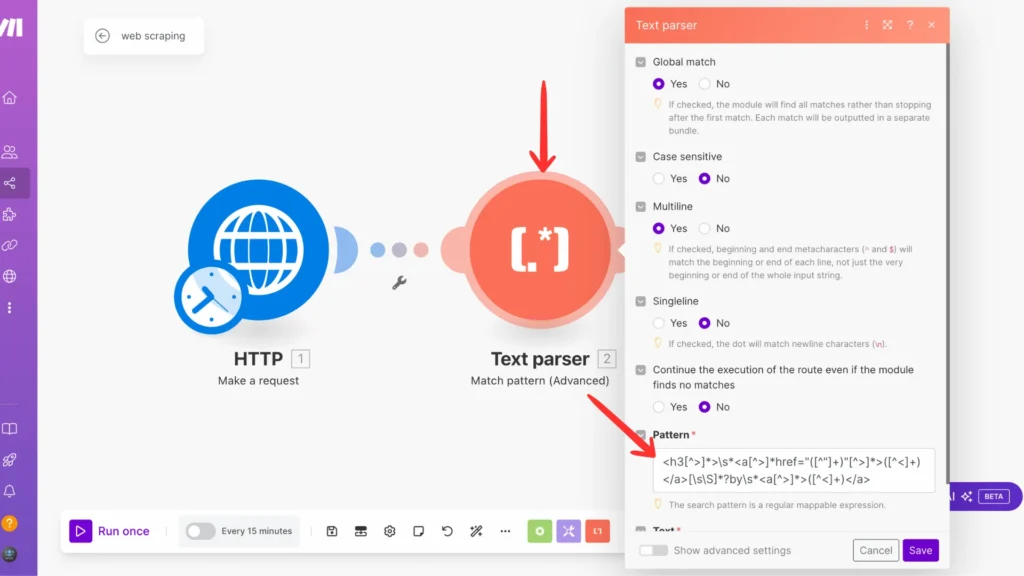
Next, we’ll connect our modules together. In the regex module’s ‘Text‘ field, you must select the ‘HTML response‘ from our previous ‘Make a request‘ module. Click on the text field to see a list of available data – look for the HTML response option. This tells Regex exactly where to look for information in our book!
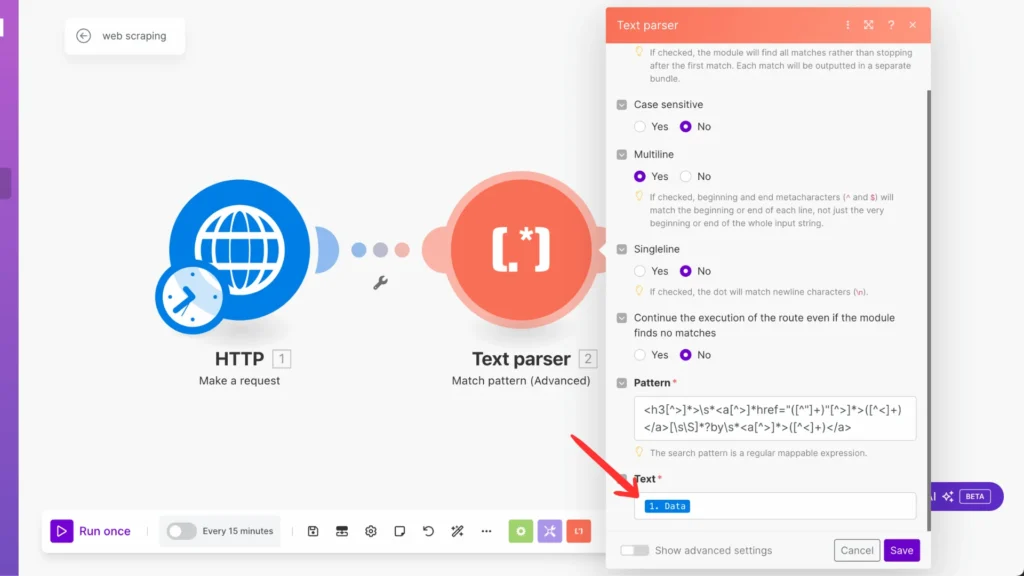
Step 6: Connect With Google Sheets
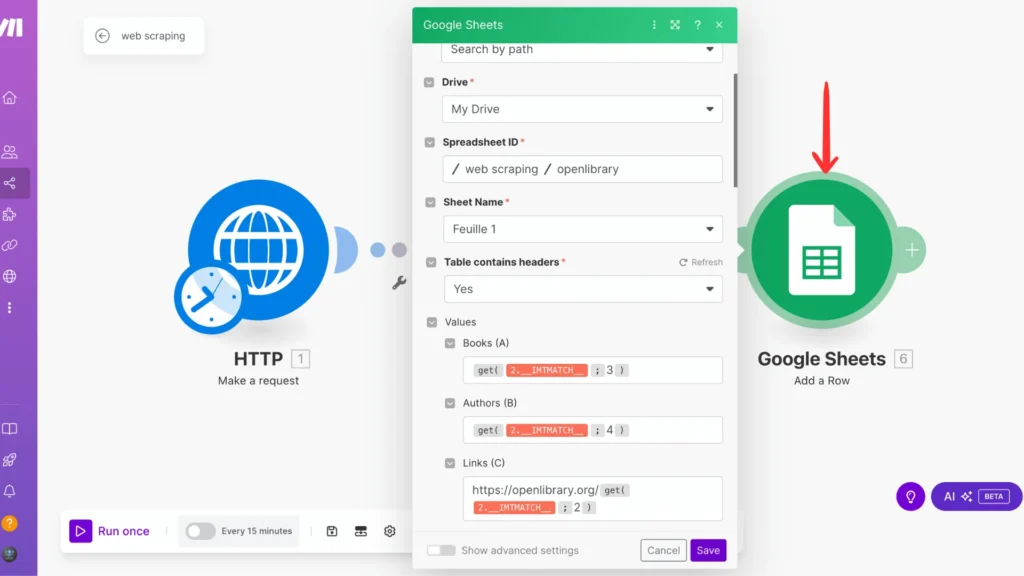
Finally, let’s connect everything to our Google Sheet! Add the ‘Google Sheets – Add a Row‘ module as our last puzzle piece. When you set it up:- Click to select your spreadsheet from the dropdown – it’ll show the one we created earlier
- Once selected, the columns we created will automatically appear (pretty neat, right?)
- Use each column’s ‘Get‘ function to match our extracted data with the right column. Click the small button with curly brackets {} next to each field, and you’ll see all the data we captured from our regex module ready to be mapped!
This way, each time our scenario runs, it’ll automatically add a new row with all our scraped-book information neatly organized in our spreadsheet.
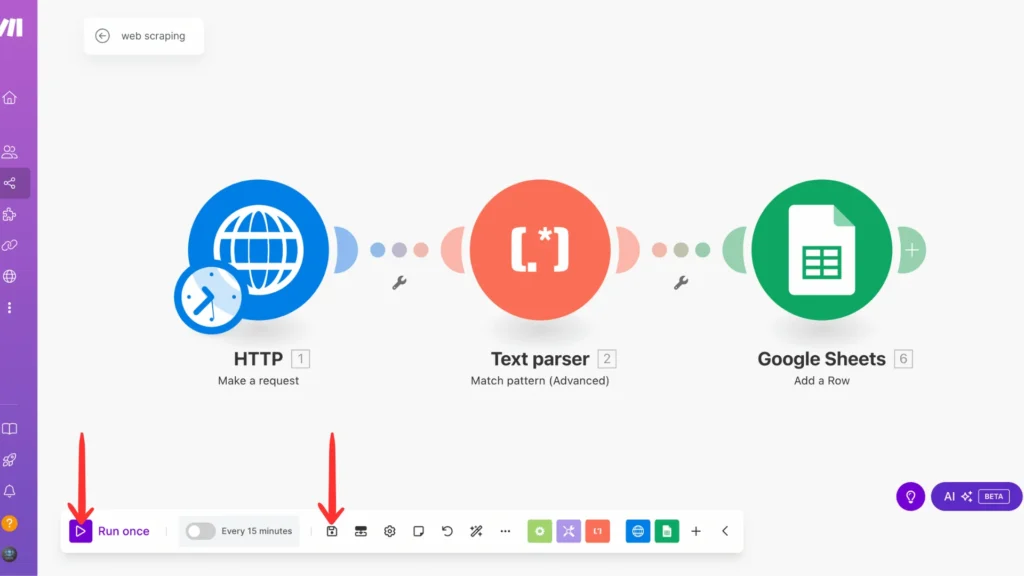
Step 7: Save And Run
Now for the exciting part – let’s bring your web scraping scenario to life! Hit that ‘Save‘ button to store all your hard work, then click ‘Run‘ to watch the magic happen. You should see your Google Sheet populate with fresh data from OpenLibrary in just a few seconds. Take a moment to check your spreadsheet and celebrate – you’ve just built your first automated web scraping system! 💪
If everything looks good, you’re all set! You can even schedule this scenario to run automatically at specific times to keep your data fresh.
Step 8: Results
And voilà! Let me show you what you’ve accomplished! Your spreadsheet should now be automatically populated with fresh book data—titles, authors, and links neatly organized in their respective columns. It’s amazing how we’ve gone from a blank Google Sheet to an automated book-tracking system in just a few simple steps!
Feel free to experiment with different websites or modify the columns to capture different information. The possibilities are endless, and you have all the tools you need to adapt this system for your web scraping projects.
Happy scraping! If you found this tutorial helpful, don’t forget to share your own creative uses for this setup – I’d love to hear what you build with it! 😊
How Web Scraping Can Help You
Web scraping can be a game-changer for businesses and individuals looking to make data-driven decisions. Instead of spending countless hours manually gathering information, web scraping automates the process and opens up exciting possibilities for your projects.
For businesses, web scraping can revolutionize market research by automatically tracking competitor prices, monitoring customer sentiment, and identifying market trends. It helps you stay ahead of the competition by providing real-time insights into your industry landscape. Imagine being notified when competitors change their prices or new products hit the market!
For researchers and analysts, web scraping simplifies data collection from multiple sources. Whether you’re gathering academic papers, social media trends, or statistical data, web scraping tools can compile this information into organized datasets ready for analysis.
Content creators and marketers can use web scraping to track trending topics, gather content ideas, and monitor their online presence. It’s like having a dedicated research assistant working 24/7 to inform you about your field.
Even for personal projects, web scraping can help you track the prices of items you want to buy, monitor job listings, or collect data for your hobby projects – all without the tedious manual work of visiting multiple websites.
Conclusion
Now, you’re equipped with the knowledge to scrape any website using Make! Remember always to follow ethical scraping practices and respect the website’s terms of service. Start small, test thoroughly, and gradually scale your scraping operations. Ready to put these skills into action? Jump into Make and create your first web scraping scenario today!
FAQs
Is it legal to scrape any website?
While web scraping is legal, you should check a website’s Terms of Service and robots.txt file. Some websites explicitly prohibit scraping, and you should respect their policies. Also, be mindful of using the scraped data and avoid collecting personal information without proper authorization.
Can make.com scrape data?
Yes! Make.com (formerly Integromat) is an excellent tool for web scraping. It provides user-friendly modules that can extract data from websites without complex coding knowledge. This tutorial shows you can easily set up automated scenarios to collect and organize web data.
How do I scrape all content from a website?
While scraping entire websites is possible, it’s best to focus on the specific data you need rather than collecting everything. Start by identifying the exact information you want, creating appropriate regex patterns or selectors for those elements, and using tools like Make.com to extract that data. Remember to respect the website’s rate limits and implement proper delays between requests to avoid overwhelming their servers.

Further Ressources
- How to Automate Contract Management with Make
- How to Build an Automated Time Tracking System on Make
- The Ultimate Guide to Data Mapping in Make
- How to Automate Employee Onboarding in Make
- How to Send Automated Emails from Google Forms Using Make
- How to Use Canva to Automate Social Media Posts with Make
- How to Automate Invoice Processing with Make
- How to Build a Customer Support System Automation in Make





